Составные типы данных
Содержание
Составные типы данных¶
При обработке массивов чисел есть несколько подходов.
Рассмотрим несколько типов составных переменных и взаимосвязи между ними. В качестве данных будем использовать текстовый файл с данными по времени реакции (reaction time, RT).
u='d/rt.tsv'
print(open(u).read(93)+' ...')
t v
9.585 0.429
16.368 0.335
23.729 0.357
30.93 0.373
40.303 0.439
46.804 0.402
55.448 0.382
...
1. Список¶
Входит в базовый комплект Python и не требует импорта библиотек.
Достоинство - универсальность, недостатки - требует перебора входящих элементов, ибо никак не предполагает их единообразия: в одном списке могут быть и числа, и строки, и сложные объекты.
#создаем пустой список
vv=[]
#открываем файл
with open(u) as f:
#пропускаем строку заголовков
print('Строка заголовков: ' + f.readline())
# из каждой строчки извлекаем число между 1-м и 2-м пробелами или табуляциями (2-ю колонку)
for l in f.readlines():
# print(v) # выводит на экран каждую строку, если разкомментировать
v = l.split()[1]
vv.append(float(v))
vv
Строка заголовков: t v
[0.429,
0.335,
0.357,
0.373,
0.439,
0.402,
0.382,
0.325,
0.4,
0.303,
0.349,
nan,
0.285,
0.288,
0.308,
0.282,
0.382,
0.338,
0.307,
0.514,
0.287,
0.316,
0.29,
0.434,
nan,
nan,
0.622,
0.402,
0.393,
0.471,
0.411,
0.431,
0.519,
0.37,
0.412,
0.385,
0.513,
0.389,
0.439,
0.443,
0.698,
0.473,
0.377,
0.372,
0.357,
0.378,
0.391,
0.396]
У списка есть только длина, но в его состав могут входить другие списки.
len(vv)
48
Сгруппируем список из 6 списочков по 8 значений в каждом.
vv6x8 = []
i = 0 #текущая позиция
for igroup in range(6):
v1 = vv[i:i+8]
vv6x8.append(v1)
i += 8 #сдвигаемся к началу следующей группы
vv6x8
[[0.429, 0.335, 0.357, 0.373, 0.439, 0.402, 0.382, 0.325],
[0.4, 0.303, 0.349, nan, 0.285, 0.288, 0.308, 0.282],
[0.382, 0.338, 0.307, 0.514, 0.287, 0.316, 0.29, 0.434],
[nan, nan, 0.622, 0.402, 0.393, 0.471, 0.411, 0.431],
[0.519, 0.37, 0.412, 0.385, 0.513, 0.389, 0.439, 0.443],
[0.698, 0.473, 0.377, 0.372, 0.357, 0.378, 0.391, 0.396]]
Необходимо правильно рассчитывать размеры, и проверять крайние группы, чтобы при указании индексов не выйти за пределы массива.
Из функций обработки в чистом Python есть только сумма. Вот так можно посчитать средние значения для каждой группы.
[sum(gr)/len(gr) for gr in vv6x8]
[0.38025000000000003, nan, 0.3585, nan, 0.43375, 0.43025]
2. Numpy Array¶
Массивы чисел, с которыми можно обращаться как с единым целым. Библиотека numpy включает функции линейной алгебры для работы с матрицами.
Типичный импорт в виде np.
import numpy as np
np.set_printoptions(suppress=True) #не использовать научную нотацию
В numpy есть функция загрузки таблиц с числами loadtxt. Поскольку в нашем файле есть заголовки (строки, а не числа) и колонки с нечисловыми значениями, то указываем дополнительные параметры: пропустить 1 ряд, использовать 2-ю колонку.
x = np.loadtxt(u, skiprows=1, usecols=(1,))
x
array([0.429, 0.335, 0.357, 0.373, 0.439, 0.402, 0.382, 0.325, 0.4 ,
0.303, 0.349, nan, 0.285, 0.288, 0.308, 0.282, 0.382, 0.338,
0.307, 0.514, 0.287, 0.316, 0.29 , 0.434, nan, nan, 0.622,
0.402, 0.393, 0.471, 0.411, 0.431, 0.519, 0.37 , 0.412, 0.385,
0.513, 0.389, 0.439, 0.443, 0.698, 0.473, 0.377, 0.372, 0.357,
0.378, 0.391, 0.396])
x.shape
(48,)
Массивы чисел в numpy могут иметь много измерений. Чтобы изменить форму массива, достаточно указать новые размеры по нужным измерениям.
X = x.reshape(-1,8)
X
array([[0.429, 0.335, 0.357, 0.373, 0.439, 0.402, 0.382, 0.325],
[0.4 , 0.303, 0.349, nan, 0.285, 0.288, 0.308, 0.282],
[0.382, 0.338, 0.307, 0.514, 0.287, 0.316, 0.29 , 0.434],
[ nan, nan, 0.622, 0.402, 0.393, 0.471, 0.411, 0.431],
[0.519, 0.37 , 0.412, 0.385, 0.513, 0.389, 0.439, 0.443],
[0.698, 0.473, 0.377, 0.372, 0.357, 0.378, 0.391, 0.396]])
X.shape
(6, 8)
type(X)
numpy.ndarray
Мы получили шесть групп значений, но в двух группах есть пропуски, помеченные nan. Чтобы пустые значения не мешали в вычислениях, можно сделать маску, которая исключит помеченные значения из вычислений.
Xmask = np.ma.masked_array(X, np.isnan(X))
type(Xmask)
numpy.ma.core.MaskedArray
С массивом можно обращаться к с единым целым. При этом можно применять разные операции к колонкам и строчкам. В случае необходимости менять форму и переворачивать (транспонировать).
Массивы numpy включают методы для базовой статистики.
X.mean()
nan
X.mean(axis=1)
array([0.38025, nan, 0.3585 , nan, 0.43375, 0.43025])
Xmask.mean(axis=1)
masked_array(data=[0.38025, 0.3164285714285714, 0.3585, 0.455,
0.43374999999999997, 0.43025],
mask=[False, False, False, False, False, False],
fill_value=1e+20)
Xmask.mean(axis=1).round(2)
masked_array(data=[0.38, 0.32, 0.36, 0.46, 0.43, 0.43],
mask=[False, False, False, False, False, False],
fill_value=1e+20)
Наличие пустых значений - типичная ситуация при анализе данных, поэтому созданы специальные функции для работы с nan.
np.nanmean(X, axis=1).round(2)
array([0.38, 0.32, 0.36, 0.46, 0.43, 0.43])
np.nanmean(X.T, axis=0).round(2)
array([0.38, 0.32, 0.36, 0.46, 0.43, 0.43])
Свойство .T (T большое) - транспонирование.
Очень удобно выполнять действия с несколькими массивами. При этом автоматически подбираются соответствия между количеством значений в каждом (Рис. 6).
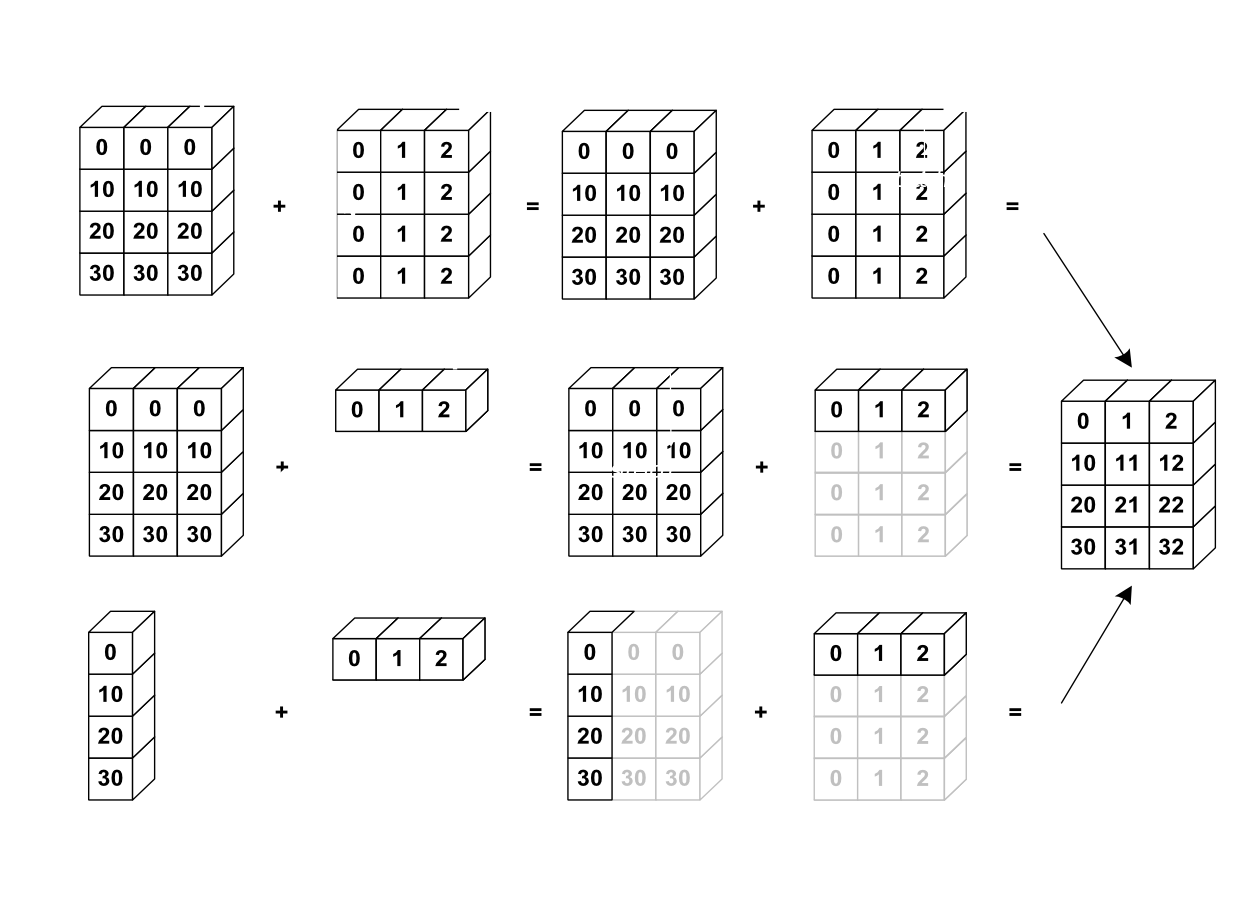
Рис. 6 Распределенное соответствие размеров при операциях с массивами.¶
Например, нормализуем массив - вычтем среднее и разделим на стандартное отклонение каждую строчку.
Xnorm = np.array((Xmask.T - Xmask.T.mean(axis=0))/Xmask.T.std(axis=0)).T.round(3)
Xnorm
array([[ 1.259, -1.168, -0.6 , -0.187, 1.517, 0.562, 0.045, -1.427],
[ 2.082, -0.335, 0.811, nan, -0.783, -0.708, -0.21 , -0.858],
[ 0.313, -0.273, -0.686, 2.071, -0.952, -0.566, -0.912, 1.005],
[ nan, nan, 2.118, -0.672, -0.786, 0.203, -0.558, -0.304],
[ 1.605, -1.2 , -0.409, -0.918, 1.492, -0.842, 0.099, 0.174],
[ 2.517, 0.402, -0.501, -0.547, -0.688, -0.491, -0.369, -0.322]])
Массив можно редуцировать до списка.
Xnorm.tolist()
[[1.259, -1.168, -0.6, -0.187, 1.517, 0.562, 0.045, -1.427],
[2.082, -0.335, 0.811, nan, -0.783, -0.708, -0.21, -0.858],
[0.313, -0.273, -0.686, 2.071, -0.952, -0.566, -0.912, 1.005],
[nan, nan, 2.118, -0.672, -0.786, 0.203, -0.558, -0.304],
[1.605, -1.2, -0.409, -0.918, 1.492, -0.842, 0.099, 0.174],
[2.517, 0.402, -0.501, -0.547, -0.688, -0.491, -0.369, -0.322]]
type(_)
list
3. Pandas DataFrame¶
Для работы со структурированными данными библиотека pandas предлагает структуры:
1-мерная Series
2-мерная DataFrame
Рекомендуемый способ представления трех- и более мерных данных - использовать таблицы с многоуровневым индексом (MultiIndex).
Типичный импорт в виде pd. Библиотека включает массу функций для удобного обращения с файлами, датами, статистикой и рисунками.
import pandas as pd
D = pd.read_table(u)
D
| t | v | |
|---|---|---|
| 0 | 9.585 | 0.429 |
| 1 | 16.368 | 0.335 |
| 2 | 23.729 | 0.357 |
| 3 | 30.930 | 0.373 |
| 4 | 40.303 | 0.439 |
| 5 | 46.804 | 0.402 |
| 6 | 55.448 | 0.382 |
| 7 | 62.401 | 0.325 |
| 8 | 68.910 | 0.400 |
| 9 | 73.463 | 0.303 |
| 10 | 77.697 | 0.349 |
| 11 | 81.661 | NaN |
| 12 | 86.385 | 0.285 |
| 13 | 90.470 | 0.288 |
| 14 | 95.114 | 0.308 |
| 15 | 99.548 | 0.282 |
| 16 | 104.056 | 0.382 |
| 17 | 105.844 | 0.338 |
| 18 | 107.955 | 0.307 |
| 19 | 109.636 | 0.514 |
| 20 | 111.487 | 0.287 |
| 21 | 113.394 | 0.316 |
| 22 | 115.732 | 0.290 |
| 23 | 117.612 | 0.434 |
| 24 | 128.119 | NaN |
| 25 | 135.000 | NaN |
| 26 | 143.557 | 0.622 |
| 27 | 151.932 | 0.402 |
| 28 | 160.933 | 0.393 |
| 29 | 168.975 | 0.471 |
| 30 | 177.819 | 0.411 |
| 31 | 184.975 | 0.431 |
| 32 | 191.480 | 0.519 |
| 33 | 195.884 | 0.370 |
| 34 | 199.594 | 0.412 |
| 35 | 203.637 | 0.385 |
| 36 | 207.373 | 0.513 |
| 37 | 211.929 | 0.389 |
| 38 | 216.615 | 0.439 |
| 39 | 219.947 | 0.443 |
| 40 | 224.455 | 0.698 |
| 41 | 226.741 | 0.473 |
| 42 | 228.837 | 0.377 |
| 43 | 230.642 | 0.372 |
| 44 | 232.313 | 0.357 |
| 45 | 234.108 | 0.378 |
| 46 | 235.799 | 0.391 |
| 47 | 238.050 | 0.396 |
При чтении таблицы создаются индексы - для наблюдений (строчек) и для переменных (колонок).
D.columns
Index(['t', 'v'], dtype='object')
D.index
RangeIndex(start=0, stop=48, step=1)
Можно задать в качестве индекса одну из колонок с данными. По-умолчанию используется автоматическая нумерация (как в этом примере).
Каждая строчка или колонка DataFrame - это серия с соответствующим индексом. К значениям можно обращаться по их индексу в любом порядке. Например, чтобы получить третье по счету значение ВР:
D['v'][2] # вначале колонка, потом позиция в колонке
0.35700000000000004
D.loc[2]['v'] # вначале строка, потом колонка
0.35700000000000004
D.loc[2,'v'] # обе координаты строка и колонка
0.35700000000000004
Способ с одновременным указанием строки и колонки является предпочтительным, потому что в одно действие происходит обращение к нужной ячейке таблицы. Именно этот способ используют для замены конкретного значения, например
D.loc[2,'v'] = D['v'].mean()
Можно использовать порядковый индекс позиции, как в массивах numpy.
D.iloc[2,1]
0.35700000000000004
Таблицы включают мощные средства манипуляции данными.
При необходимости разбиения массива данных на группы признаки принадлежности к разным группам добавляют в виде новых колонок, а уже информацию в этих колонках используют в разных сочетаниях при отборе подвыборок и сравнительном анализе.
Добавим в качестве группового признака номер группы для разделения всей последовательности на 6 одинаковых групп, идущих друг за другом.
ngroup = 6
D['g'] = np.kron(range(1,ngroup+1), np.ones(int(len(D)/ngroup), int))
Например, чтобы посчитать среднее ВР для разных МСИ (в колонке 'g'), можно сделать так:
D.groupby('g')['v'].mean()
g
1 0.380250
2 0.316429
3 0.358500
4 0.455000
5 0.433750
6 0.430250
Name: v, dtype: float64
Таблицы и Серии подходят для использования в операциях линейной алгебры из numpy. Если надо, значения таблицы можно извлечь в виде массива или в виде списка.
D.values
array([[ 9.585, 0.429, 1. ],
[ 16.368, 0.335, 1. ],
[ 23.729, 0.357, 1. ],
[ 30.93 , 0.373, 1. ],
[ 40.303, 0.439, 1. ],
[ 46.804, 0.402, 1. ],
[ 55.448, 0.382, 1. ],
[ 62.401, 0.325, 1. ],
[ 68.91 , 0.4 , 2. ],
[ 73.463, 0.303, 2. ],
[ 77.697, 0.349, 2. ],
[ 81.661, nan, 2. ],
[ 86.385, 0.285, 2. ],
[ 90.47 , 0.288, 2. ],
[ 95.114, 0.308, 2. ],
[ 99.548, 0.282, 2. ],
[104.056, 0.382, 3. ],
[105.844, 0.338, 3. ],
[107.955, 0.307, 3. ],
[109.636, 0.514, 3. ],
[111.487, 0.287, 3. ],
[113.394, 0.316, 3. ],
[115.732, 0.29 , 3. ],
[117.612, 0.434, 3. ],
[128.119, nan, 4. ],
[135. , nan, 4. ],
[143.557, 0.622, 4. ],
[151.932, 0.402, 4. ],
[160.933, 0.393, 4. ],
[168.975, 0.471, 4. ],
[177.819, 0.411, 4. ],
[184.975, 0.431, 4. ],
[191.48 , 0.519, 5. ],
[195.884, 0.37 , 5. ],
[199.594, 0.412, 5. ],
[203.637, 0.385, 5. ],
[207.373, 0.513, 5. ],
[211.929, 0.389, 5. ],
[216.615, 0.439, 5. ],
[219.947, 0.443, 5. ],
[224.455, 0.698, 6. ],
[226.741, 0.473, 6. ],
[228.837, 0.377, 6. ],
[230.642, 0.372, 6. ],
[232.313, 0.357, 6. ],
[234.108, 0.378, 6. ],
[235.799, 0.391, 6. ],
[238.05 , 0.396, 6. ]])
И, наоборот, из массива можно сделать датафрейм (таблицу). Если не указать индексы - они создадутся автоматически.
pd.DataFrame(X)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.429 | 0.335 | 0.357 | 0.373 | 0.439 | 0.402 | 0.382 | 0.325 |
| 1 | 0.400 | 0.303 | 0.349 | NaN | 0.285 | 0.288 | 0.308 | 0.282 |
| 2 | 0.382 | 0.338 | 0.307 | 0.514 | 0.287 | 0.316 | 0.290 | 0.434 |
| 3 | NaN | NaN | 0.622 | 0.402 | 0.393 | 0.471 | 0.411 | 0.431 |
| 4 | 0.519 | 0.370 | 0.412 | 0.385 | 0.513 | 0.389 | 0.439 | 0.443 |
| 5 | 0.698 | 0.473 | 0.377 | 0.372 | 0.357 | 0.378 | 0.391 | 0.396 |
Посмотрим типы переменных, созданных разными способами.
type(vv), type(X), type(D['g']), type(D)
(list, numpy.ndarray, pandas.core.series.Series, pandas.core.frame.DataFrame)