Формирование набора данных
Содержание
Формирование набора данных¶
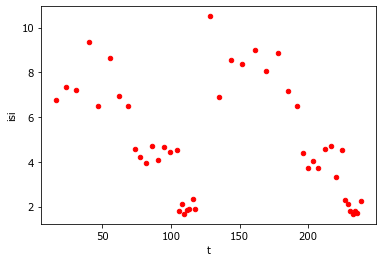
Как мы уже выяснили в наборе данных из теста «Баланс внимания»: 1-я колонка - моменты времени предъявления стимулов, 2-я колонка - время реакции, с.
Основной фактор, который изменялся в тесте - это частота предъявления стимулов. Поскольку мы знаем время предъявления стимулов, то можем посчитать межстимульный интервал (МСИ). На основе анализа МСИ мы сможем добавить в набор данных все необходимые для дальнейшего анализа признаки.
D = pd.read_table('d/rt.tsv')
D['isi']=D.t.diff() #разница между соседними моментами времени
D.plot('t','isi',kind='scatter', color='r');
Фактор модальности¶
На основании рассчитанных межстимульных интервалов (МСИ, isi) можно выделить блоки реакций на зрительные стимулы с изменением МСИ от 8 до 2 с и на слуховые стимулы с аналогичной динамикой МСИ.
Так как мы работаем с единым блоком данных, то эти признаки можно добавить в виде дополнительных колонок в эту же таблицу.
Способов задать пороговые значения для выделения групповых признаков может быть много. Желательно использовать более универсальные.
Например, можно ввести условие для отбора слуховых реакций D.t > 130 , т.е. время стимула более 130 с от начала теста. Однако, в другом тесте продолжительность может измениться, поэтому надежнее использовать разницу в МСИ. Для этого дифференцируем ряд значений МСИ. Переход МСИ от 2 к 8 с возможен только однажды - при смене модальности в середине теста. В этом месте разница между последовательными значениями МСИ резко возрастает более чем на 5 с.
D.isi.diff()>5
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 False
12 False
13 False
14 False
15 False
16 False
17 False
18 False
19 False
20 False
21 False
22 False
23 False
24 True
25 False
26 False
27 False
28 False
29 False
30 False
31 False
32 False
33 False
34 False
35 False
36 False
37 False
38 False
39 False
40 False
41 False
42 False
43 False
44 False
45 False
46 False
47 False
Name: isi, dtype: bool
iA=(D.isi.diff()>5).argmax() #сохраняем позицию, где условие истинно.
iA
24
Это индекс того места в ряде значений, где начинаются слуховые реакции
# создадим колонку с одним значением v - visual
D['mod']='v'
# значение после найденого индекса заменим на 'a' - audial
D.loc[iA:, 'mod'] = 'a'
D.tail()
| t | v | isi | mod | |
|---|---|---|---|---|
| 43 | 230.642 | 0.372 | 1.805 | a |
| 44 | 232.313 | 0.357 | 1.671 | a |
| 45 | 234.108 | 0.378 | 1.795 | a |
| 46 | 235.799 | 0.391 | 1.691 | a |
| 47 | 238.050 | 0.396 | 2.251 | a |
Фактор частоты¶
Из процедуры тестирования мы знаем, что МСИ в тесте изменялся в ряду [8, 4, 2] с добавлением случайной вариации.
Чтобы распределить значения по группам можно найти крайние значения в ряду изменения МСИ и все промежуточные между ними зачислить в ту же группу.
(D.isi<5).argmax()
9
(D.loc[iA:,'isi']<5).argmax()
9
# создадим колонку с одним значением 8
D['g']=8
# заменим значения в колонке 'g' на 4 там, где начинаются МСИ менее 5 с
iV4 = (D.isi<5).argmax() #где начинаются 4
iA4 = iA + (D[iA:].isi<5).argmax()
D.loc[iV4:iA-1, 'g'] = D.loc[iA4:, 'g']= 4
# заменим значения в колонке 'g' на 2 там, где начинаются МСИ менее 3 с
iV2 = (D.isi<3).argmax() #где начинаются 4
iA2 = iA + (D[iA:].isi<3).argmax()
D.loc[iV2:iA-1, 'g']= D.loc[iA2:, 'g']= 2
D
| t | v | isi | mod | g | |
|---|---|---|---|---|---|
| 0 | 9.585 | 0.429 | NaN | v | 8 |
| 1 | 16.368 | 0.335 | 6.783 | v | 8 |
| 2 | 23.729 | 0.357 | 7.361 | v | 8 |
| 3 | 30.930 | 0.373 | 7.201 | v | 8 |
| 4 | 40.303 | 0.439 | 9.373 | v | 8 |
| 5 | 46.804 | 0.402 | 6.501 | v | 8 |
| 6 | 55.448 | 0.382 | 8.644 | v | 8 |
| 7 | 62.401 | 0.325 | 6.953 | v | 8 |
| 8 | 68.910 | 0.400 | 6.509 | v | 8 |
| 9 | 73.463 | 0.303 | 4.553 | v | 4 |
| 10 | 77.697 | 0.349 | 4.234 | v | 4 |
| 11 | 81.661 | NaN | 3.964 | v | 4 |
| 12 | 86.385 | 0.285 | 4.724 | v | 4 |
| 13 | 90.470 | 0.288 | 4.085 | v | 4 |
| 14 | 95.114 | 0.308 | 4.644 | v | 4 |
| 15 | 99.548 | 0.282 | 4.434 | v | 4 |
| 16 | 104.056 | 0.382 | 4.508 | v | 4 |
| 17 | 105.844 | 0.338 | 1.788 | v | 2 |
| 18 | 107.955 | 0.307 | 2.111 | v | 2 |
| 19 | 109.636 | 0.514 | 1.681 | v | 2 |
| 20 | 111.487 | 0.287 | 1.851 | v | 2 |
| 21 | 113.394 | 0.316 | 1.907 | v | 2 |
| 22 | 115.732 | 0.290 | 2.338 | v | 2 |
| 23 | 117.612 | 0.434 | 1.880 | v | 2 |
| 24 | 128.119 | NaN | 10.507 | a | 8 |
| 25 | 135.000 | NaN | 6.881 | a | 8 |
| 26 | 143.557 | 0.622 | 8.557 | a | 8 |
| 27 | 151.932 | 0.402 | 8.375 | a | 8 |
| 28 | 160.933 | 0.393 | 9.001 | a | 8 |
| 29 | 168.975 | 0.471 | 8.042 | a | 8 |
| 30 | 177.819 | 0.411 | 8.844 | a | 8 |
| 31 | 184.975 | 0.431 | 7.156 | a | 8 |
| 32 | 191.480 | 0.519 | 6.505 | a | 8 |
| 33 | 195.884 | 0.370 | 4.404 | a | 4 |
| 34 | 199.594 | 0.412 | 3.710 | a | 4 |
| 35 | 203.637 | 0.385 | 4.043 | a | 4 |
| 36 | 207.373 | 0.513 | 3.736 | a | 4 |
| 37 | 211.929 | 0.389 | 4.556 | a | 4 |
| 38 | 216.615 | 0.439 | 4.686 | a | 4 |
| 39 | 219.947 | 0.443 | 3.332 | a | 4 |
| 40 | 224.455 | 0.698 | 4.508 | a | 4 |
| 41 | 226.741 | 0.473 | 2.286 | a | 2 |
| 42 | 228.837 | 0.377 | 2.096 | a | 2 |
| 43 | 230.642 | 0.372 | 1.805 | a | 2 |
| 44 | 232.313 | 0.357 | 1.671 | a | 2 |
| 45 | 234.108 | 0.378 | 1.795 | a | 2 |
| 46 | 235.799 | 0.391 | 1.691 | a | 2 |
| 47 | 238.050 | 0.396 | 2.251 | a | 2 |
Теперь у нас есть готовый набор данных, с которым легко проводить анализ по группам, а также выявлять взаимосвязи между данными в разных колонках.
# можно сохранить готовый набор данных с другим именем
D.to_csv('rtgotov.csv', index=False)
Распределение МСИ¶
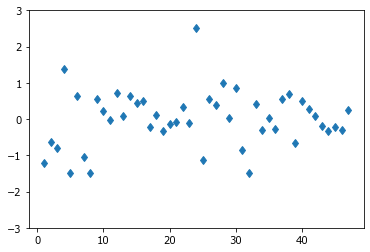
Итак у нас есть групповой фактор, задающий средний МСИ. Также мы можем определить конкретные МСИ по задержке между стимулами.
Давайте посмотрим отклонение отдельных МСИ от групповых.
(D.isi - D.g).plot(lw=0, marker='d', ylim=(-3,3));
(D.isi - D.g).hist(bins=arange(-3,3,0.25));
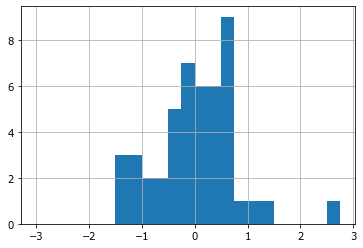
Создается впечатление, что вариация МСИ происходила по нормальному закону - гистограмма в центре выше и снижается к краям. Однако, мы не учли, что тут смешаны и длинные и короткие МСИ.
Пересчитаем остатки, нормализовав их по групповому значению.
r=((D.isi - D.g)/D.g)
r.plot(lw=0, marker='d', ylim=(-3,3));

# из-за выбросов приходится задавать жесткие границы классов
r.hist(bins=arange(-1,1,0.05));
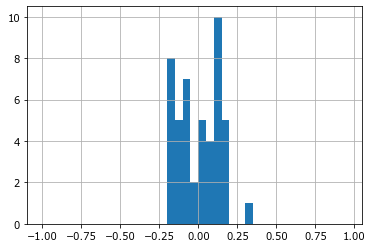
r.hist(bins=arange(-.5,.5,0.1));
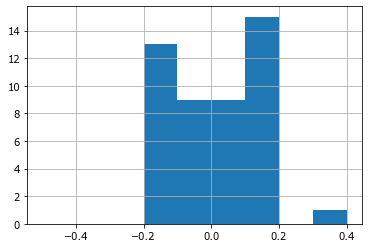
Столбцы гистограммы не снижаются к бокам и при этом видны четкие границы (без учета двух выборосов, которые не видны на рисунке) - это признаки равномерного распределения в заданных пределах \(\pm 20\%\).